Recently I decided to use Google´s Photos app to manage all my photos. My collection is about ~7000 photos so it took me some time to create the albums and organize it. My intention was to do a back up from time to time using Google Takeout to keep the photos backed-up outside cloud as well.
Google Takeout is a service for everyone with Google account allowing the users to download back any previously updated data. It means you can download back all your uploaded photos too - so I tried.
I thought the Google is reliable in matter of storing/searching/downloading data, well it is Google, right? Who else should?
..I was wrong =>
After you succesfully download your data you will end up with several *.zip files:
Next logical step is to unzip the files and hope that every photo you ever uploaded to Google Photo is there:)
In my case the disappointment was pretty fast. After first glance in some of the extracted albums I can see some of the *.jpg files are missing. An example:
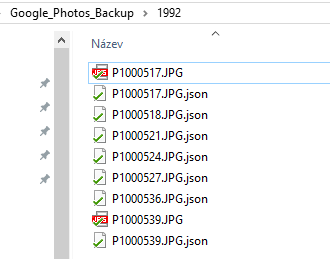
You can see all I got from 1992 album is just two photos. There should be seven of them. At first I thought “ok, some sync issue”..however I got the same output after several days..I thought the files have to be somehow indexed by Google..but even after some time I got the same results again…Ok Google, I´m not that patient:)
In order to get “lost” photos back we can leverage two facts:
- the JSON files are downloaded correctly for each file
- the JSON files contains link to the photo on Google server
How many photos are missing = were not “Taken out”?
library(tidyverse)
library(jsonlite)
library(fs)tibble(json_orig_path = dir_ls("D:/GoogleDrive/Archiv/Google_Photos_Backup", recursive = TRUE, type = "file")) %>%
# exclude "metadata.json" files - each folder has one
filter(!str_detect(json_orig_path, "metadata.json")) %>%
# extract file extension
mutate(extension = str_extract(json_orig_path, "\\.[A-Za-z0-9_]+$")) %>%
count(extension) -> t
t## # A tibble: 8 x 2
## extension n
## <chr> <int>
## 1 .f 1
## 2 .jp 1
## 3 .jpg 1698
## 4 .JPG 553
## 5 .jpg_ 2
## 6 .json 7131
## 7 .mp4 28
## 8 .wmv 8..there is missing quite a lot of files as each JSON file should have corresponding media file - that´s disappointing.
t %>%
count(extension == ".json", wt = n)## # A tibble: 2 x 2
## `extension == ".json"` nn
## <lgl> <int>
## 1 FALSE 2291
## 2 TRUE 7131It means ~70% is missing!
Really Google, 30% “taken out” only?
Well, that´s not what I consider sufficient. I know the Google Photos is free, but this is not what I would expect from leading IT company. Besides, I´m not the only one with this issue based on Google´s forum, yet no feedack or reaction from Google.
Anyway, let´s to do it on our own. As mentioned, we can leverage the JSON files as they contain the url (to Google server) to each photo. My target is to save the files into the same folder (album) as where is the JSON file.
Let´s make a tibble of all JSON files (Photos) we want to extract url from.
df_raw <- tibble(json_orig_path = dir_ls("D:/Google_Photos_Backup",
recursive = TRUE,
regex = "*.json$"))
df_raw## # A tibble: 7,295 x 1
## json_orig_path
## <fs::path>
## 1 D:/Google_Photos_Backup/1984/metadata.json
## 2 D:/Google_Photos_Backup/1984/P1010212.JPG.json
## 3 D:/Google_Photos_Backup/1984/P1010213.JPG.json
## 4 D:/Google_Photos_Backup/1984/P1010214.JPG.json
## 5 D:/Google_Photos_Backup/1984/P1010215.JPG.json
## 6 D:/Google_Photos_Backup/1984/P1010216.JPG.json
## 7 D:/Google_Photos_Backup/1985/metadata.json
## 8 D:/Google_Photos_Backup/1985/P1000439.JPG.json
## 9 D:/Google_Photos_Backup/1987/metadata.json
## 10 D:/Google_Photos_Backup/1987/P1000442.JPG.json
## # ... with 7,285 more rowsdf_sub <- df_raw %>%
# exclude "metadata.json" files - each folder has one
filter(!str_detect(json_orig_path, "metadata")) %>%
# add list-column with json content
mutate(data = json_orig_path %>% map(fromJSON)) %>%
# extract link to google server
mutate(google_path = map_chr(data, "url")) %>%
# exclude video files
filter(!str_detect(google_path, "video-downloads")) %>%
# extract filename
mutate(filename = map_chr(data, "title")) %>%
# create destination path incl filename
mutate(pic_dest_path = paste(dirname(json_orig_path),filename,sep = "/")) %>%
# add rowid
rowid_to_column()
df_sub %>% glimpse()## Observations: 7,055
## Variables: 6
## $ rowid <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, ...
## $ json_orig_path <fs::path> "D:/Google_Photos_Backup/1984/P1010212.JPG...
## $ data <list> [["P1010212.JPG", "", "https://lh3.googleuserc...
## $ google_path <chr> "https://lh3.googleusercontent.com/-zKvbiXTAtdg...
## $ filename <chr> "P1010212.JPG", "P1010213.JPG", "P1010214.JPG",...
## $ pic_dest_path <chr> "D:/Google_Photos_Backup/1984/P1010212.JPG", "D...Now we are ready to download the files:
df_sub %>%
pwalk(function(google_path, pic_dest_path, rowid, ...){
if (!file_exists(pic_dest_path)){
download.file(url = google_path, destfile = pic_dest_path, mode = "wb", quiet = TRUE)
cat(paste(rowid,"\tdownloaded"))
} else {
cat(paste(rowid,"\texist"))
}
cat("\n")
})Let´s check it again after download:
tibble(json_orig_path = dir_ls("D:/Google_Photos_Backup", recursive = TRUE, type = "file")) %>%
# exclude "metadata.json" files - each folder has one
filter(!str_detect(json_orig_path, "metadata.json")) %>%
# extract file extension
mutate(extension = str_extract(json_orig_path, "\\.[A-Za-z0-9_]+$")) %>%
count(extension) -> t
t## # A tibble: 8 x 2
## extension n
## <chr> <int>
## 1 .f 1
## 2 .jp 1
## 3 .jpg 3188
## 4 .JPG 3921
## 5 .jpg_ 2
## 6 .json 7131
## 7 .mp4 28
## 8 .wmv 8t %>%
count(extension == ".json", wt = n)## # A tibble: 2 x 2
## `extension == ".json"` nn
## <lgl> <int>
## 1 FALSE 7149
## 2 TRUE 7131That´s much better, isn´t it?