library(tidyverse)
library(broom)
library(lubridate)
library(scales)df_prec_raw <- readRDS("../../static/data/chmu_srazky.rds")
df_temp_raw <- readRDS("../../static/data/chmu_teploty.rds")df_prec_raw## # A tibble: 9,744 x 5
## year_month year month region precipitation
## <dttm> <chr> <chr> <chr> <dbl>
## 1 1961-01-01 00:00:00 1961 Jan Česká republika 22
## 2 1961-01-01 00:00:00 1961 Jan Praha a Středočeský 15
## 3 1961-01-01 00:00:00 1961 Jan Jihočeský 14
## 4 1961-01-01 00:00:00 1961 Jan Plzeňský 22
## 5 1961-01-01 00:00:00 1961 Jan Karlovarský 39
## 6 1961-01-01 00:00:00 1961 Jan Ústecký 23
## 7 1961-01-01 00:00:00 1961 Jan Liberecký 41
## 8 1961-01-01 00:00:00 1961 Jan Královéhradecký 38
## 9 1961-01-01 00:00:00 1961 Jan Pardubický 21
## 10 1961-01-01 00:00:00 1961 Jan Vysočina 16
## # ... with 9,734 more rowsdf_temp_raw## # A tibble: 9,744 x 5
## year_month year month region temperature
## <dttm> <chr> <chr> <chr> <dbl>
## 1 1961-01-01 00:00:00 1961 Jan Česká republika -3.4
## 2 1961-01-01 00:00:00 1961 Jan Praha a Středočeský -2.8
## 3 1961-01-01 00:00:00 1961 Jan Jihočeský -3.9
## 4 1961-01-01 00:00:00 1961 Jan Plzeňský -3.2
## 5 1961-01-01 00:00:00 1961 Jan Karlovarský -3.4
## 6 1961-01-01 00:00:00 1961 Jan Ústecký -3.4
## 7 1961-01-01 00:00:00 1961 Jan Liberecký -3.7
## 8 1961-01-01 00:00:00 1961 Jan Královéhradecký -3.3
## 9 1961-01-01 00:00:00 1961 Jan Pardubický -3.4
## 10 1961-01-01 00:00:00 1961 Jan Vysočina -3.9
## # ... with 9,734 more rowsMerge both dataset together. Check if relevant columns are identical first.
map2(df_prec_raw, df_temp_raw, identical)## $year_month
## [1] TRUE
##
## $year
## [1] TRUE
##
## $month
## [1] TRUE
##
## $region
## [1] TRUE
##
## $precipitation
## [1] FALSEdf <- bind_cols(df_prec_raw, df_temp_raw) %>%
select(year_month, year, month, region, temperature, precipitation) %>%
gather(key, value, -year_month, -year, -month, -region) %>%
mutate(season = case_when(
str_detect(month, "Dec|Jan|Feb") ~ "Winter",
str_detect(month, "Mar|Apr|May") ~ "Spring",
str_detect(month, "Jun|Jul|Aug") ~ "Autumn",
str_detect(month, "Sep|Oct|Nov") ~ "Summer"))
df## # A tibble: 19,488 x 7
## year_month year month region key value season
## <dttm> <chr> <chr> <chr> <chr> <dbl> <chr>
## 1 1961-01-01 00:00:00 1961 Jan Česká republika temperat~ -3.4 Winter
## 2 1961-01-01 00:00:00 1961 Jan Praha a Středoče~ temperat~ -2.8 Winter
## 3 1961-01-01 00:00:00 1961 Jan Jihočeský temperat~ -3.9 Winter
## 4 1961-01-01 00:00:00 1961 Jan Plzeňský temperat~ -3.2 Winter
## 5 1961-01-01 00:00:00 1961 Jan Karlovarský temperat~ -3.4 Winter
## 6 1961-01-01 00:00:00 1961 Jan Ústecký temperat~ -3.4 Winter
## 7 1961-01-01 00:00:00 1961 Jan Liberecký temperat~ -3.7 Winter
## 8 1961-01-01 00:00:00 1961 Jan Královéhradecký temperat~ -3.3 Winter
## 9 1961-01-01 00:00:00 1961 Jan Pardubický temperat~ -3.4 Winter
## 10 1961-01-01 00:00:00 1961 Jan Vysočina temperat~ -3.9 Winter
## # ... with 19,478 more rowsWhat was the question?
Claim - “The precipitation in Czech Republic decreases over last decades.”
df %>%
filter(key == "precipitation") %>%
filter(region == "Česká republika") %>%
ggplot(aes(year_month, value)) +
geom_col() +
geom_smooth(method = "lm") +
scale_x_datetime(labels = date_format("%Y"), date_breaks = "1 year") +
theme(axis.text.x = element_text(angle = 75, hjust = 1)) +
labs(y = "precipitation [mm]", x = "year") +
facet_wrap(~region, scales = "free")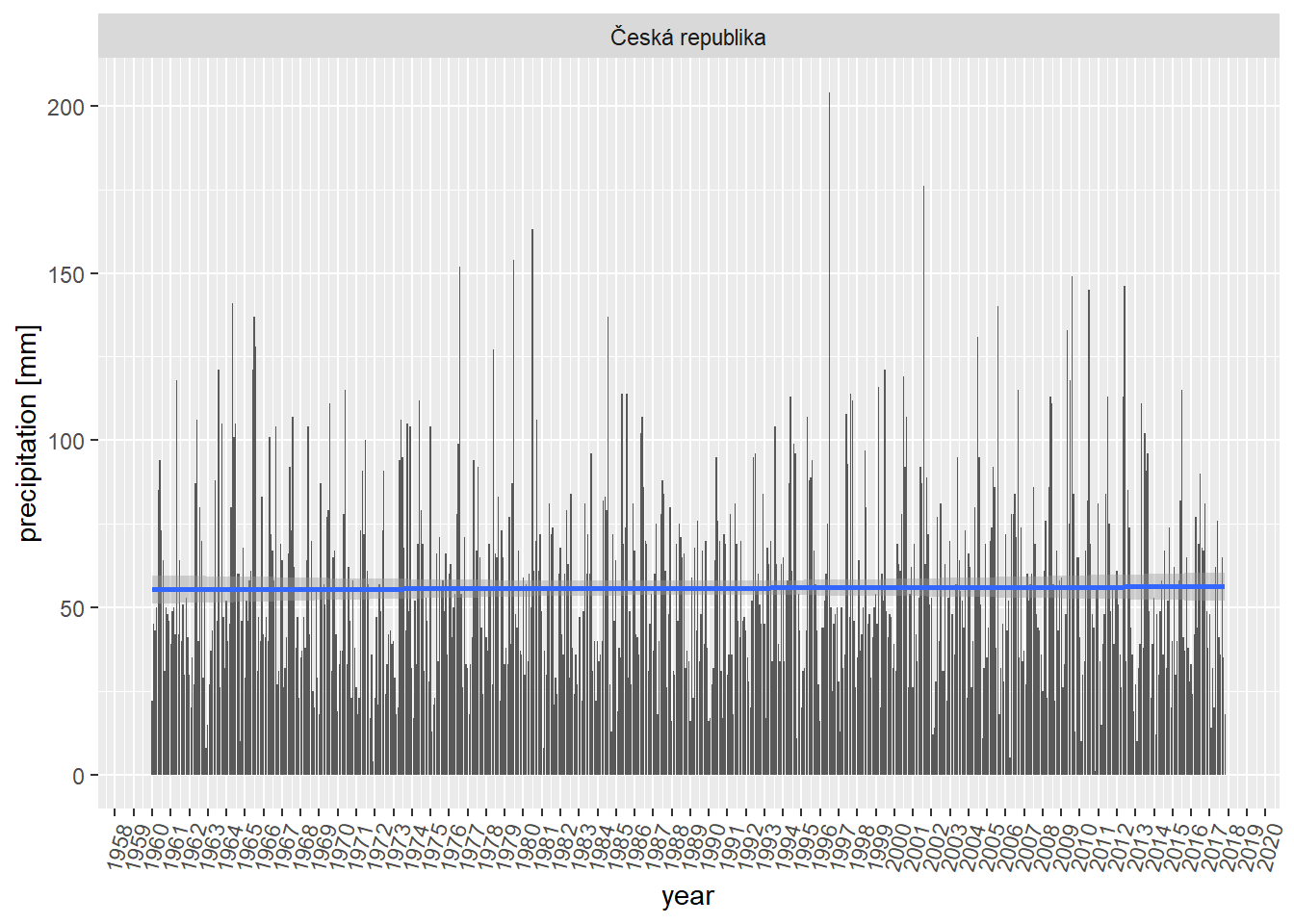
Nope (on average).
Claim - “It rains less and less every summer in Czech Republic.”
df %>%
filter(key == "precipitation") %>%
filter(region == "Česká republika") %>%
ggplot(aes(year_month, value)) +
geom_col() +
geom_smooth(method = "lm") +
# coord_flip() +
scale_x_datetime(labels = date_format("%Y"), date_breaks = "1 year") +
theme(axis.text.x = element_text(angle = 75, hjust = 1)) +
labs(y = "precipitation [mm]", x = "year") +
facet_wrap(~season, scales = "free")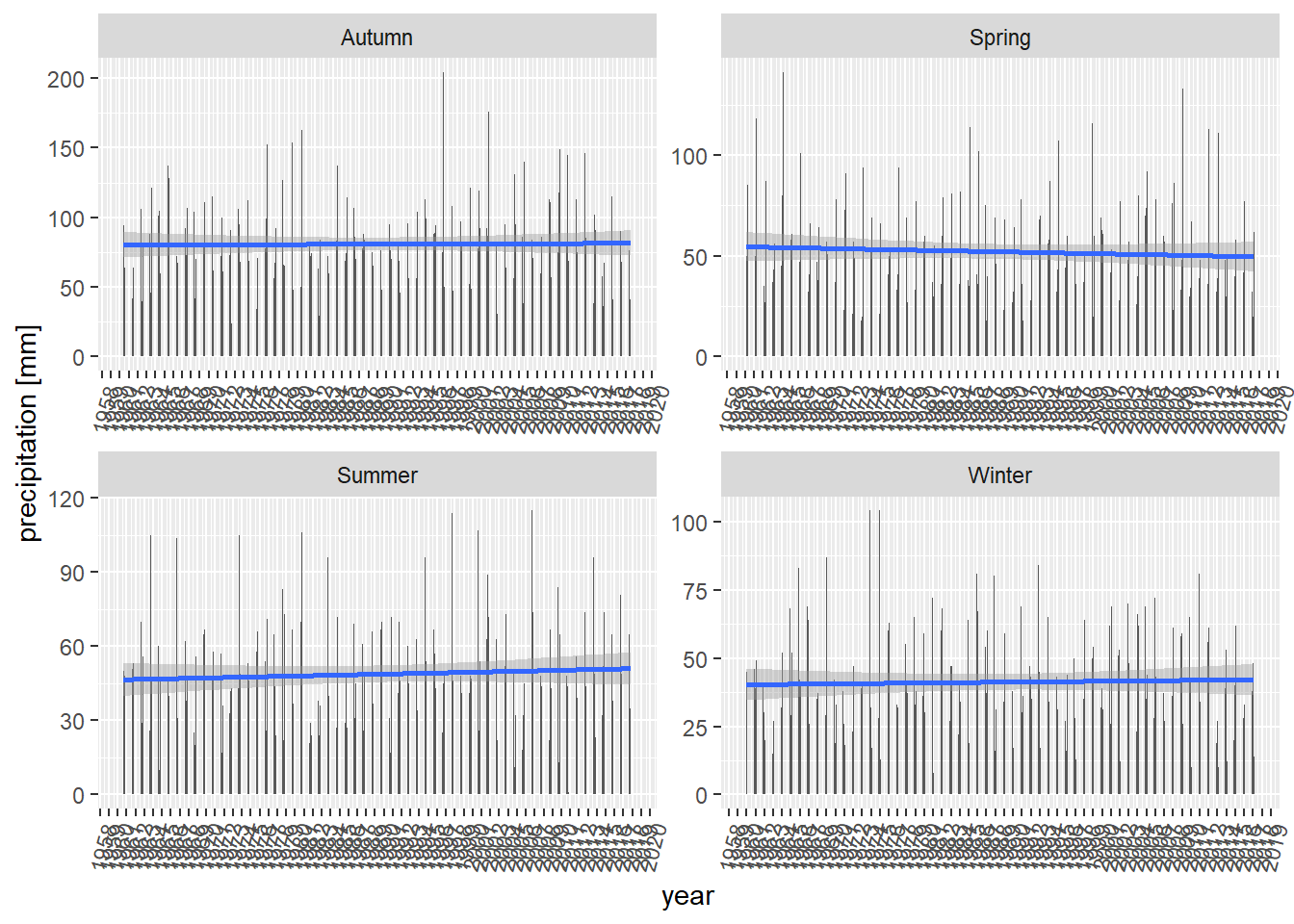
Well, seems to be quite stable, no drama here.
Claim - “The temperature in Czech Republic increases over last decades.”
df %>%
filter(key == "temperature") %>%
filter(region == "Česká republika") %>%
ggplot(aes(year_month, value)) +
geom_col() +
geom_smooth(method = "lm") +
scale_x_datetime(labels = date_format("%Y"), date_breaks = "1 year") +
theme(axis.text.x = element_text(angle = 75, hjust = 1)) +
labs(y = "°C", x = "year") +
facet_wrap(~region)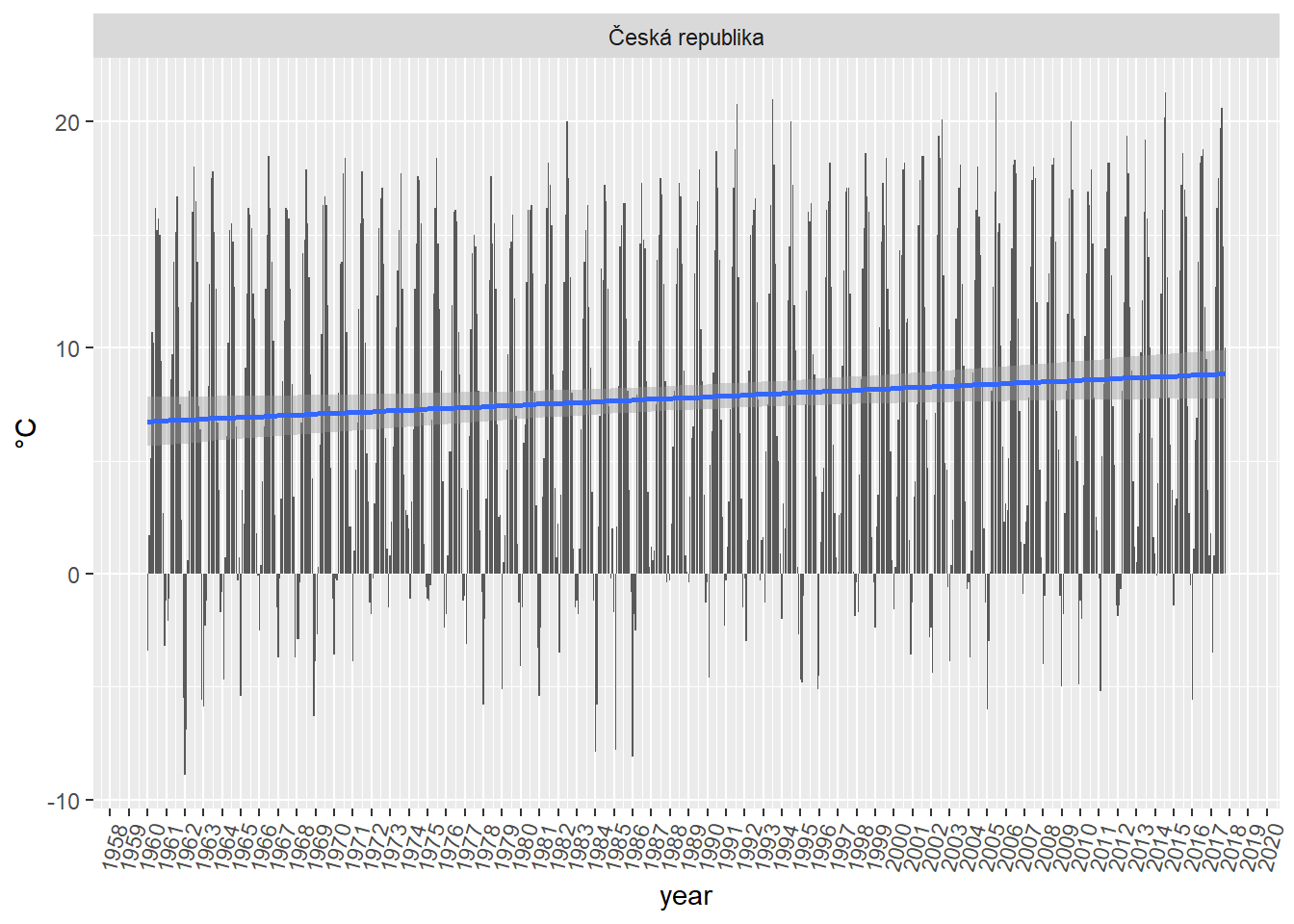
Yes, it does increase. On average by:
df %>%
filter(key == "temperature") %>%
filter(region == "Česká republika") %>%
mutate(year = year %>% as.integer()) %>%
group_by(year) %>%
summarise(temp_avg_year = mean(value)) %>%
lm(temp_avg_year~year, data = .) %>%
tidy() %>%
pull(estimate) %>%
.[[2]] %>%
round(3)## [1] 0.031..°C per year.