# load libraries
library(tidyverse)
library(shiny)Basic data wrangling first
Load and check the data structure
# load data
raw <- read_csv("../../static/data/movie_data.csv")
# structure of data
glimpse(raw)## Observations: 5,043
## Variables: 28
## $ color <chr> "Color", "Color", "Color", "Color", ...
## $ director_name <chr> "James Cameron", "Gore Verbinski", "...
## $ num_critic_for_reviews <dbl> 723, 302, 602, 813, NA, 462, 392, 32...
## $ duration <dbl> 178, 169, 148, 164, NA, 132, 156, 10...
## $ director_facebook_likes <dbl> 0, 563, 0, 22000, 131, 475, 0, 15, 0...
## $ actor_3_facebook_likes <dbl> 855, 1000, 161, 23000, NA, 530, 4000...
## $ actor_2_name <chr> "Joel David Moore", "Orlando Bloom",...
## $ actor_1_facebook_likes <dbl> 1000, 40000, 11000, 27000, 131, 640,...
## $ gross <dbl> 760505847, 309404152, 200074175, 448...
## $ genres <chr> "Action|Adventure|Fantasy|Sci-Fi", "...
## $ actor_1_name <chr> "CCH Pounder", "Johnny Depp", "Chris...
## $ movie_title <chr> "Avatar ", "Pirates of the Caribbean...
## $ num_voted_users <dbl> 886204, 471220, 275868, 1144337, 8, ...
## $ cast_total_facebook_likes <dbl> 4834, 48350, 11700, 106759, 143, 187...
## $ actor_3_name <chr> "Wes Studi", "Jack Davenport", "Step...
## $ facenumber_in_poster <dbl> 0, 0, 1, 0, 0, 1, 0, 1, 4, 3, 0, 0, ...
## $ plot_keywords <chr> "avatar|future|marine|native|paraple...
## $ movie_imdb_link <chr> "http://www.imdb.com/title/tt0499549...
## $ num_user_for_reviews <dbl> 3054, 1238, 994, 2701, NA, 738, 1902...
## $ language <chr> "English", "English", "English", "En...
## $ country <chr> "USA", "USA", "UK", "USA", NA, "USA"...
## $ content_rating <chr> "PG-13", "PG-13", "PG-13", "PG-13", ...
## $ budget <dbl> 237000000, 300000000, 245000000, 250...
## $ title_year <dbl> 2009, 2007, 2015, 2012, NA, 2012, 20...
## $ actor_2_facebook_likes <dbl> 936, 5000, 393, 23000, 12, 632, 1100...
## $ imdb_score <dbl> 7.9, 7.1, 6.8, 8.5, 7.1, 6.6, 6.2, 7...
## $ aspect_ratio <dbl> 1.78, 2.35, 2.35, 2.35, NA, 2.35, 2....
## $ movie_facebook_likes <dbl> 33000, 0, 85000, 164000, 0, 24000, 0...# show character and numeric variables separately
raw %>%
select_if(is.character) %>%
glimpse## Observations: 5,043
## Variables: 12
## $ color <chr> "Color", "Color", "Color", "Color", NA, "Color...
## $ director_name <chr> "James Cameron", "Gore Verbinski", "Sam Mendes...
## $ actor_2_name <chr> "Joel David Moore", "Orlando Bloom", "Rory Kin...
## $ genres <chr> "Action|Adventure|Fantasy|Sci-Fi", "Action|Adv...
## $ actor_1_name <chr> "CCH Pounder", "Johnny Depp", "Christoph Waltz...
## $ movie_title <chr> "Avatar ", "Pirates of the Caribbean: At World...
## $ actor_3_name <chr> "Wes Studi", "Jack Davenport", "Stephanie Sigm...
## $ plot_keywords <chr> "avatar|future|marine|native|paraplegic", "god...
## $ movie_imdb_link <chr> "http://www.imdb.com/title/tt0499549/?ref_=fn_...
## $ language <chr> "English", "English", "English", "English", NA...
## $ country <chr> "USA", "USA", "UK", "USA", NA, "USA", "USA", "...
## $ content_rating <chr> "PG-13", "PG-13", "PG-13", "PG-13", NA, "PG-13...raw %>%
select_if(is.numeric) %>%
glimpse## Observations: 5,043
## Variables: 16
## $ num_critic_for_reviews <dbl> 723, 302, 602, 813, NA, 462, 392, 32...
## $ duration <dbl> 178, 169, 148, 164, NA, 132, 156, 10...
## $ director_facebook_likes <dbl> 0, 563, 0, 22000, 131, 475, 0, 15, 0...
## $ actor_3_facebook_likes <dbl> 855, 1000, 161, 23000, NA, 530, 4000...
## $ actor_1_facebook_likes <dbl> 1000, 40000, 11000, 27000, 131, 640,...
## $ gross <dbl> 760505847, 309404152, 200074175, 448...
## $ num_voted_users <dbl> 886204, 471220, 275868, 1144337, 8, ...
## $ cast_total_facebook_likes <dbl> 4834, 48350, 11700, 106759, 143, 187...
## $ facenumber_in_poster <dbl> 0, 0, 1, 0, 0, 1, 0, 1, 4, 3, 0, 0, ...
## $ num_user_for_reviews <dbl> 3054, 1238, 994, 2701, NA, 738, 1902...
## $ budget <dbl> 237000000, 300000000, 245000000, 250...
## $ title_year <dbl> 2009, 2007, 2015, 2012, NA, 2012, 20...
## $ actor_2_facebook_likes <dbl> 936, 5000, 393, 23000, 12, 632, 1100...
## $ imdb_score <dbl> 7.9, 7.1, 6.8, 8.5, 7.1, 6.6, 6.2, 7...
## $ aspect_ratio <dbl> 1.78, 2.35, 2.35, 2.35, NA, 2.35, 2....
## $ movie_facebook_likes <dbl> 33000, 0, 85000, 164000, 0, 24000, 0...Trim the movie_title variable
Types of variables seems to be reasonably assigned. For some reason there ia a whitespace at the end of each movie_title. Let´s fix it with str_trim from stringr library.
# remove whitespaces from movie_title
df <- raw %>%
mutate(movie_title = str_trim(movie_title))
df$movie_title %>% head## [1] "Avatar"
## [2] "Pirates of the Caribbean: At World's End"
## [3] "Spectre"
## [4] "The Dark Knight Rises"
## [5] "Star Wars: Episode VII - The Force Awakens"
## [6] "John Carter"No more whitespaces.
Remove duplicated movies
Are there some duplicated movies?
# count of observations (movies)
nrow(df)## [1] 5043# count of unique movies
df %>%
distinct(movie_title) %>%
count()## # A tibble: 1 x 1
## n
## <int>
## 1 4916# or using dplyr´s n_distinct function
n_distinct(df$movie_title)## [1] 4916Alternative:
# any duplicated?
any(duplicated(df$movie_title))## [1] TRUE# sum of duplicated movies
sum(duplicated(df$movie_title))## [1] 127Yes, there are some, let´s exclude them.
# remove duplicates
df <- df[!duplicated(df$movie_title),]
# count of unique movies after removing of duplicates
df %>%
distinct(movie_title) %>%
count()## # A tibble: 1 x 1
## n
## <int>
## 1 4916Simple exploratory analysis
Top 20 movies according to IMDB scores
First check the num_voted_users of movies with top 10 imdb_scores.
df %>%
arrange(desc(imdb_score)) %>%
slice(1:20) %>%
arrange(num_voted_users) %>%
select(movie_title,num_voted_users) %>%
print(n=10)## # A tibble: 20 x 2
## movie_title num_voted_users
## <chr> <dbl>
## 1 Towering Inferno 10
## 2 Kickboxer: Vengeance 246
## 3 Dekalog 12590
## 4 It's Always Sunny in Philadelphia 133415
## 5 Fargo 170055
## 6 Daredevil 213483
## 7 12 Angry Men 447785
## 8 The Good, the Bad and the Ugly 503509
## 9 The Godfather: Part II 790926
## 10 Star Wars: Episode V - The Empire Strikes Back 837759
## # ... with 10 more rowsObviously, there is some issue in data. For example only 10 voters for movie “Towering inferno” seems not to be plausible. Assuming the IMDB scores are correctly collected let´s exclude the movies with less than 10 000 votes. It seems to be resonable threshold. In addition color the bars by country of origin.
# plot the top 20 movies and color by country
df %>%
filter(num_voted_users > 10000) %>%
arrange(desc(imdb_score)) %>%
slice(1:20) %>%
ggplot(aes(reorder(movie_title, imdb_score), imdb_score, fill = country)) +
geom_bar(stat = "identity") +
scale_y_continuous(breaks = seq(0,10,1)) +
coord_flip() +
labs(title = "Top 20 movies according to IMDB scores",
subtitle = "by country",
y = "IMDB score",
x = "Movie title") +
theme(plot.title = element_text(face = "bold",
size = 16,
hjust = 1),
plot.subtitle = element_text(face = "italic",
size = 11,
hjust = 0)
)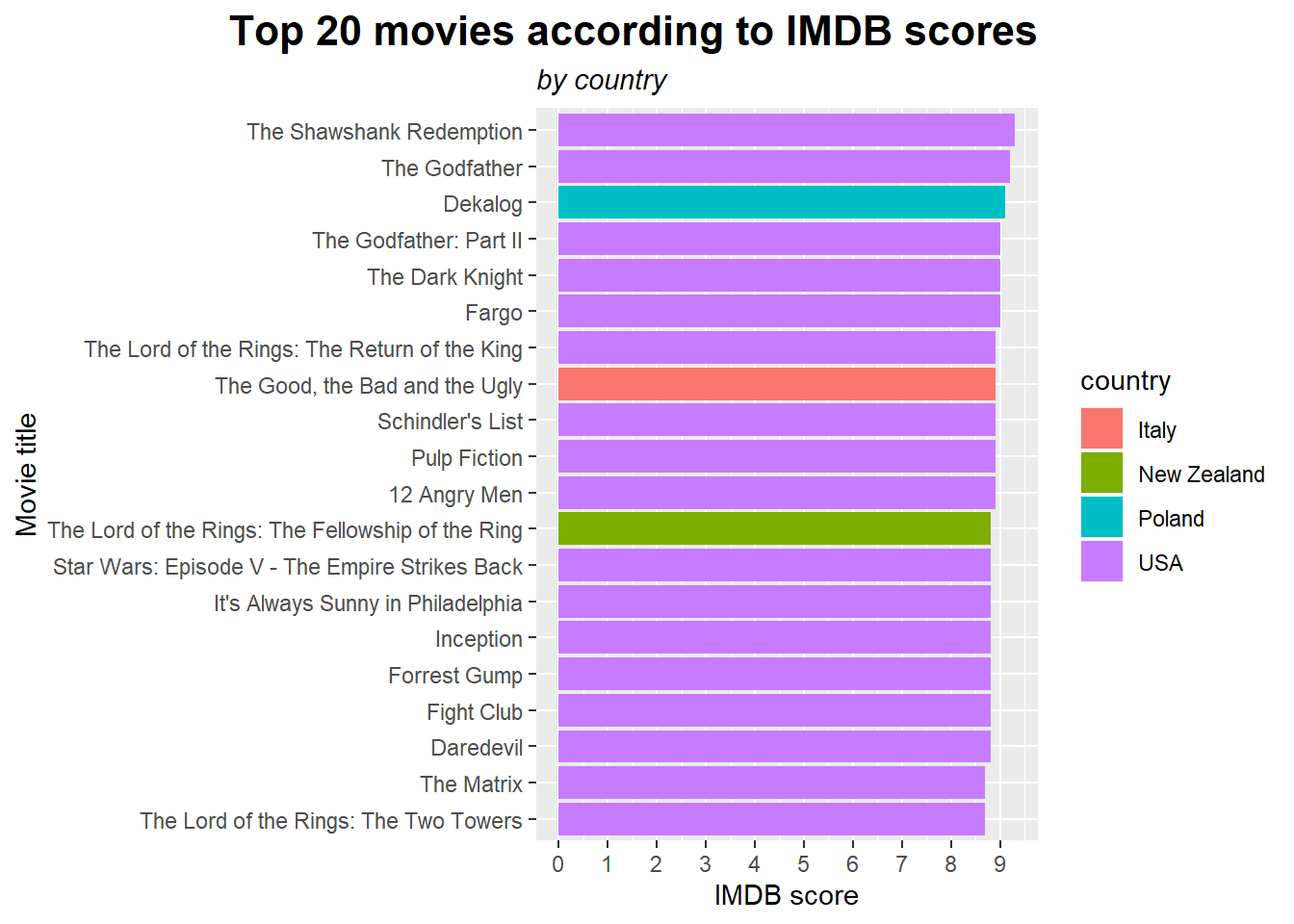
As expected, most of the movies were produced in US.
Top n movies by country
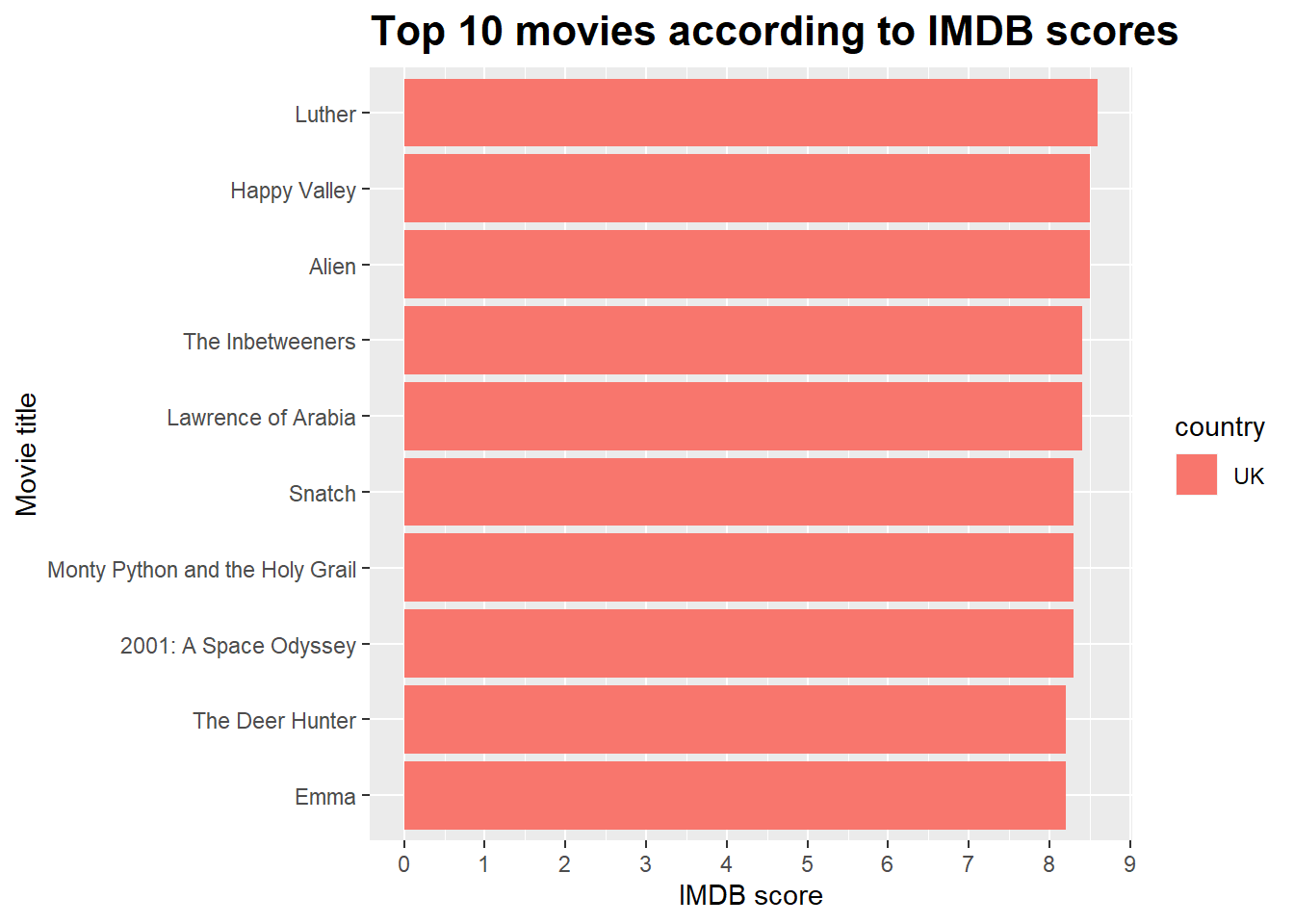
Say, I´m interested in top 10 movies from UK only.
# plot the top 10 movies from UK
df %>%
filter(num_voted_users > 10000) %>%
filter(country %in% c("UK")) %>%
arrange(desc(imdb_score)) %>%
slice(1:10) %>%
ggplot(aes(reorder(movie_title, imdb_score), imdb_score, fill = country)) +
geom_bar(stat = "identity") +
scale_y_continuous(breaks = seq(0,10,1)) +
coord_flip() +
labs(title = "Top 10 movies according to IMDB scores",
y = "IMDB score",
x = "Movie title") +
theme(plot.title = element_text(face = "bold", size = 16, hjust = 0),
plot.subtitle = element_text(face = "italic", size = 11, hjust = 0))